Total Ownership Clarity.
Optimized from Day 1.
Enterprise-grade AI deployment with intelligent development workflows. 95% success rate with structured AI-assisted development protocols.
Enterprise-grade AI deployment with intelligent development workflows. 95% success rate with structured AI-assisted development protocols.
In a landscape dominated by walled gardens and complex managed services, LLMFuze empowers you with unparalleled control, transparency, and cost-efficiency. See how we stack up against common alternatives:
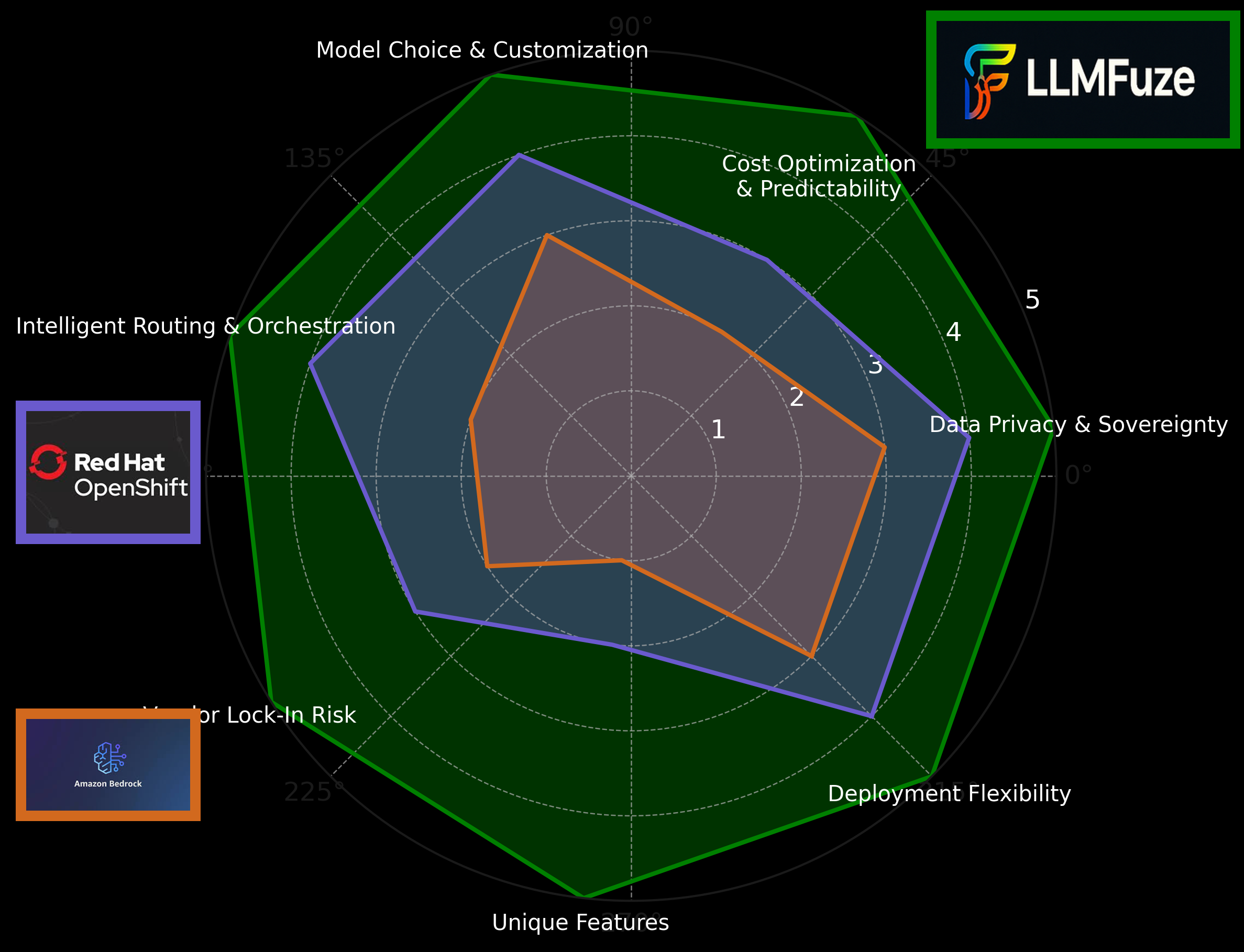
| Feature / Differentiator | LLMFuze | AWS Bedrock | Red Hat OpenShift AI |
|---|---|---|---|
| Intelligent Routing & Orchestration (RRLM) | 🟢 Adaptive, learning-based routing | 🟠 Basic routing; API gateway features | 🟠 Workflow orchestration (Kubeflow) |
| Deployment Flexibility | 🟢 Edge, Blend, Cloud – Total Control | 🟠 Primarily Cloud (Managed Service) | 🟢 On-Prem, Hybrid, Cloud (OpenShift) |
| True Data Privacy & Sovereignty | 🟢 Maximum with Edge & TP Add-on | 🟠 Managed service; data policies apply | 🟠 Strong on-prem; cloud policy dependent |
| Cost Optimization & Predictability | 🟢 Superior ROI with Edge; RRLM | 🔴 Usage-based; complex to predict | 🟠 Platform subscription + resource usage |
| Model Choice & Customization | 🟢 BYOM, OSS, Fine-tuning, Private GPT-4 | 🟠 Curated FMs; limited BYOM | 🟢 Supports various models; MLOps focus |
| Vendor Lock-In Risk | 🟢 Minimal; open standards | 🔴 Higher; deep AWS integration | 🟠 Moderate; OpenShift platform tied |
| TrulyPrivate™ GPT-4/Advanced Models | 🟢 Unique Add-on for secure VPC hosting | 🔴 Not directly comparable; public APIs | 🔴 Not directly comparable |
| AI-Assisted Development Protocols | 🟢 DISRUPT Protocol: 95% success rate, enterprise-grade | 🔴 No structured development methodology | 🔴 No AI development workflow automation |
| Speed to Innovation | 🟢 Rapid with Cloud; strategic depth with AI workflows | 🟠 Fast for standard FMs; customization slow | 🟠 Platform setup required; MLOps robust |
LLMFuze offers the freedom to innovate on your terms, with your data, under your control.
Whether you deploy Edge for full control, Blend for hybrid agility, or Cloud for rapid orchestration, LLMFuze ensures you know your numbers. No mystery costs. Just the freedom to choose the right fit—backed by data.
LLMFuze includes the revolutionary DISRUPT Protocol—a structured AI-assisted development methodology achieving 95% success rates with enterprise-grade stability and comprehensive error handling.
Comprehensive codebase analysis with devil's advocate review, git history analysis, and workspace state management.
Methodological approach using Occam's Razor, first principles thinking, and least invasive implementation strategies.
Surgical code changes with comprehensive validation, regression testing, and automated rollback capabilities.
LLMFuze is the only AI platform offering structured, enterprise-grade AI-assisted development workflows with proven reliability metrics.
Explore how Edge, Blend, and Cloud solutions align with your organizational needs. From high-security compliance to cost-efficient API access—LLMFuze adapts to your strategy.
| LLMFuze Product Line | Edge | Blend | Cloud |
|---|---|---|---|
| Target Audience | Security- and compliance-focused enterprises with advanced development workflows. TP (Truly Private) hosts OpenAI like GPTs privately! RRLM (Routing Reinforcement Language Model) adds personalization! DISRUPT Protocol ensures reliable AI-assisted development. | Teams needing domain-focused AI with internal+external orchestration. RRLM can optionally optimize flows as an add-on. DISRUPT Protocol available. | Startups and lean teams needing instant GPT access without infra, but want their data anonymized and encrypted on the way and from the Cloud. Basic development support only. |
| ROI Profile | 🔥 Highest ROI over time. TP adds compliance value. RRLM improves cost-efficiency. | ⚖️ Balanced ROI. Improves over time with RRLM. | 🚀 High initial ROI. Costs grow linearly. |
| Analogy | Owning a fleet. TP = armored. RRLM = intelligent dispatch. | Uber with trained repeat drivers. RRLM picks optimal model. | Using Uber for every ride. Fast, but adds up. |
| Deployment Mode | Self-hosted LLMs with GPT UI, RBAC, SSO. TP = GPT-4 VPC. RRLM = adaptive logic. | Hybrid GPT + local LLMs. RRLM governs orchestration. | Cloud-only API routing through proxy. No infra. |
| Model Source | LLaMA 3 or OSS by default. TP enables private GPT-4. | OSS models + external APIs. RRLM optimizes per task. | External APIs only (OpenAI, Anthropic). |
| Routing Logic | Manual routing baseline. RRLM enables intelligent routing decisions. | RRLM manages hybrid routing and fallback control. | Static config fallback between API providers. |
| RRLM Capability | ✅ RRLM optional for learning and fallback decisions. | ✅ Included. Routes between domain models and APIs. | ❌ Not supported. Fixed routing only. |
| Customization | ✅ SSO, admin UI, usage dashboard. TP + RRLM expand functionality. | ✅ GPT portal, admin UX, local/external blend. RRLM-enhanced. | ✅ Simple GPT UI. No RRLM or TP extensions. |
| Data Privacy | ✅ Full data sovereignty. No data leaves org. TP ensures GPT privacy. | 🟡 Medium privacy. API use still needed. RRLM helps localize. | 🔴 Data leaves org. Proxy must secure outbound. |
| Monitoring | ✅ Full integration with Prometheus, Grafana, Jaeger | ✅ Prometheus & Grafana pre-integrated. Add Jaeger optionally. | ❌ External APIs only. Limited observability. |
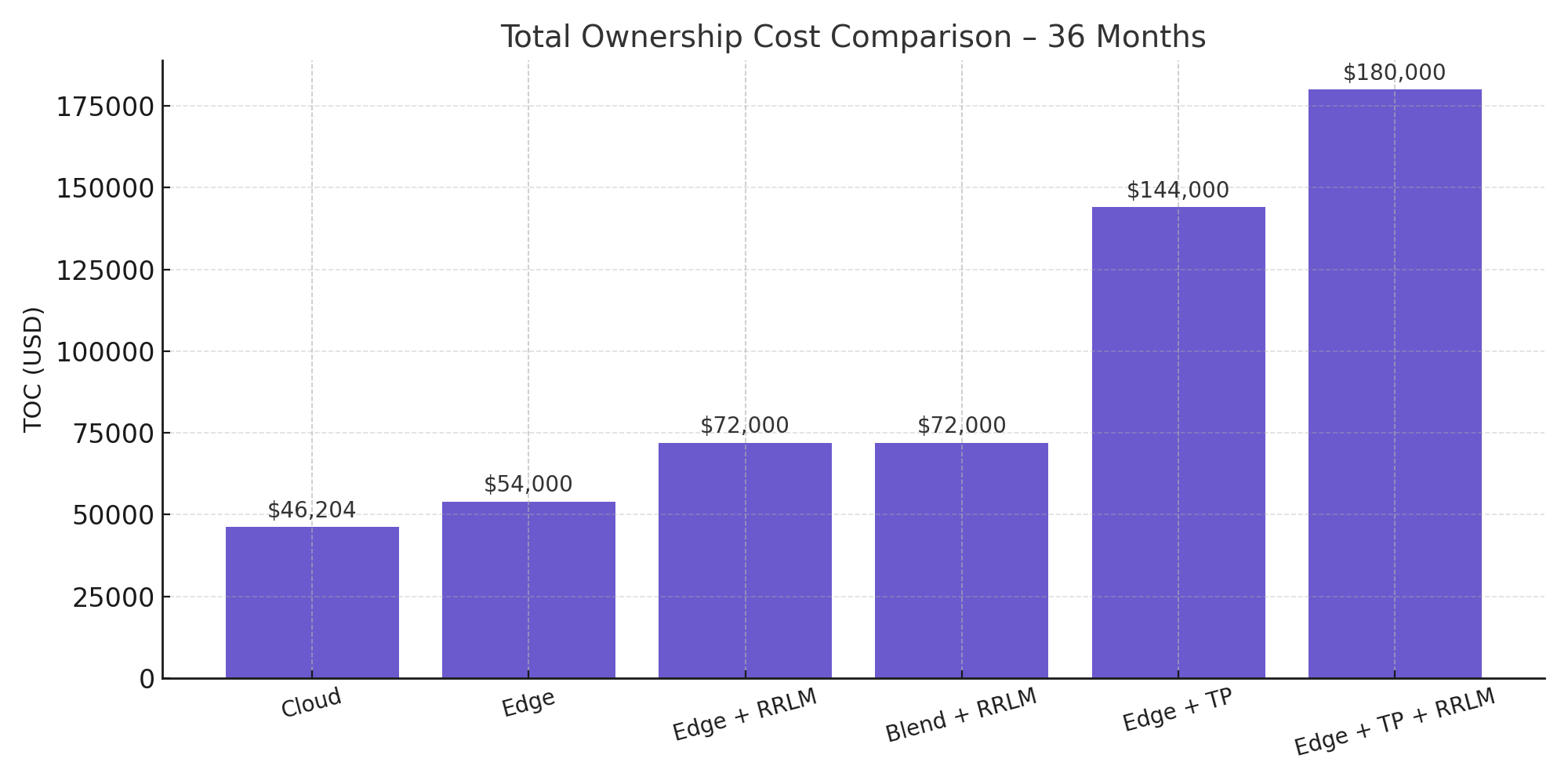
| TOC Range (6-36mo) | $8.5k → $16k → $22k | $13k → $19k → $27k | $17k → $28k → $45k |
| Upfront Setup Cost | $3K | $2K | $0 |
| Inference Latency | ⚡ Fastest (local GPU serving) | ⚡ Fast + fallback mix | 🕓 Network dependent |
| SSO / Admin Dashboard | ✅ Full suite | ✅ Optional add-on | ❌ Basic API key auth only |
| Security Tier | 🔐 High – meets FedRAMP with TP | 🟡 Medium | 🔴 Low unless hardened proxy added |
| Model Switching | ✅ Live switch + historical comparisons | ✅ Manual + RRLM override | ❌ One API set per deployment |
| LLM Fine-Tuning | ✅ OSS fine-tune capable | 🟡 Some models tunable, not all | ❌ Not available (API use only) |
| Content Safety | ✅ Full control over filters | 🟡 Shared safety layer + local rules | 🔴 Dependent on API provider policies |
| Auditing & Logging | ✅ Custom audit pipeline | ✅ Logs blend of traffic | ❌ No visibility into API handling |
| TP Support (Truly Private) | ✅ Add-on enables GPT-4 VPC | 🟡 Optional at higher cost | ❌ Not available |
| RRLM Support | ✅ Add-on enhances local learning | ✅ Included to boost hybrid logic | ❌ Not compatible |
| Language Support | ✅ Multilingual OSS options | ✅ OSS + API mix | 🟡 Dependent on provider |
| Onboarding Time | ~2 weeks (hardware setup) | ~1 week (hybrid config) | Instant (API key provisioning) |
| Ongoing Support | ✅ SLA-backed, 24/7 enterprise support | ✅ 24/5 chat + scheduled escalations | 🟡 Community-based / email fallback |
| License Flexibility | ✅ Fully open source stack + audit rights | 🟡 Mixed license dependency | ❌ Bound by commercial API terms |
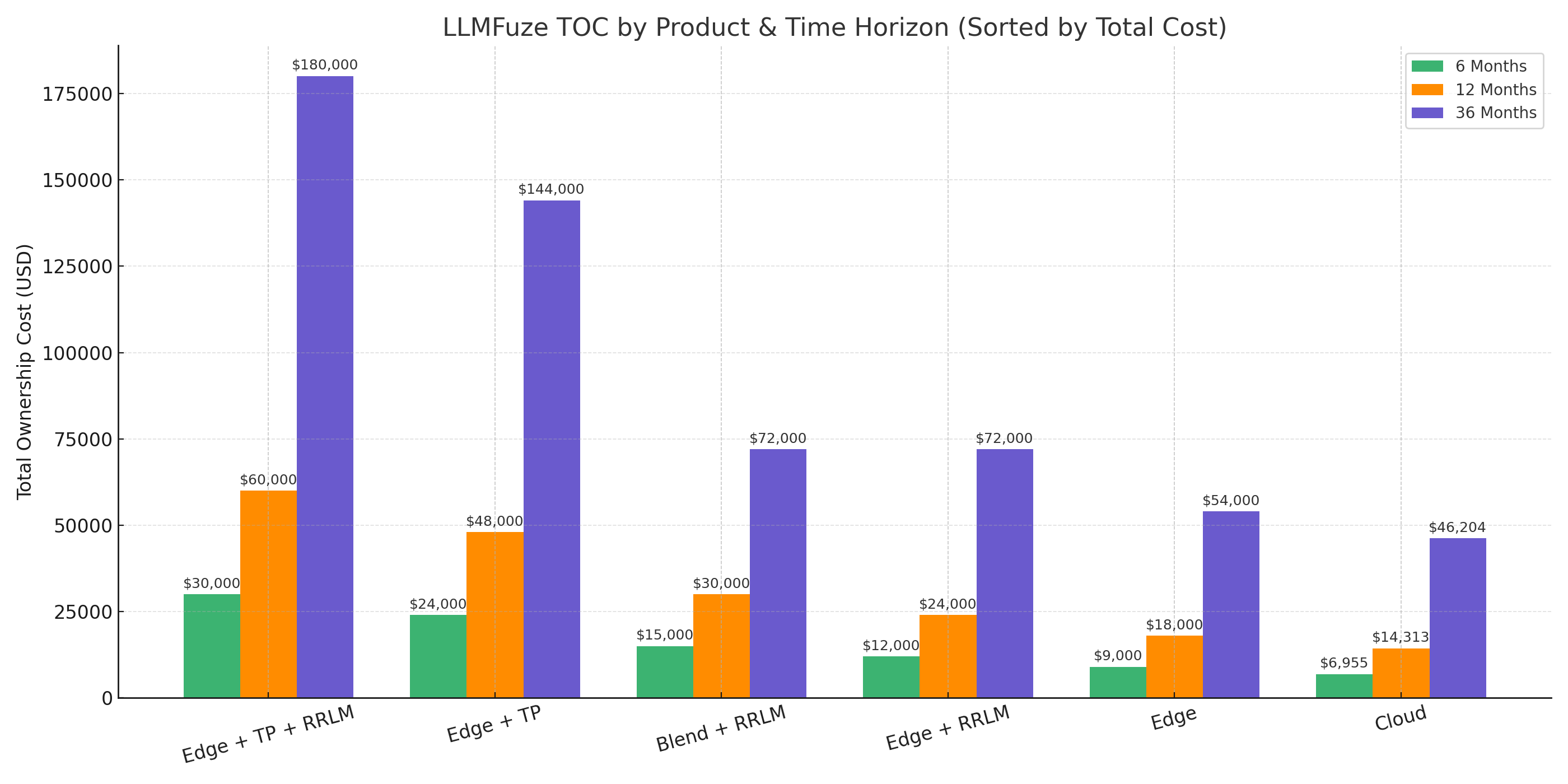
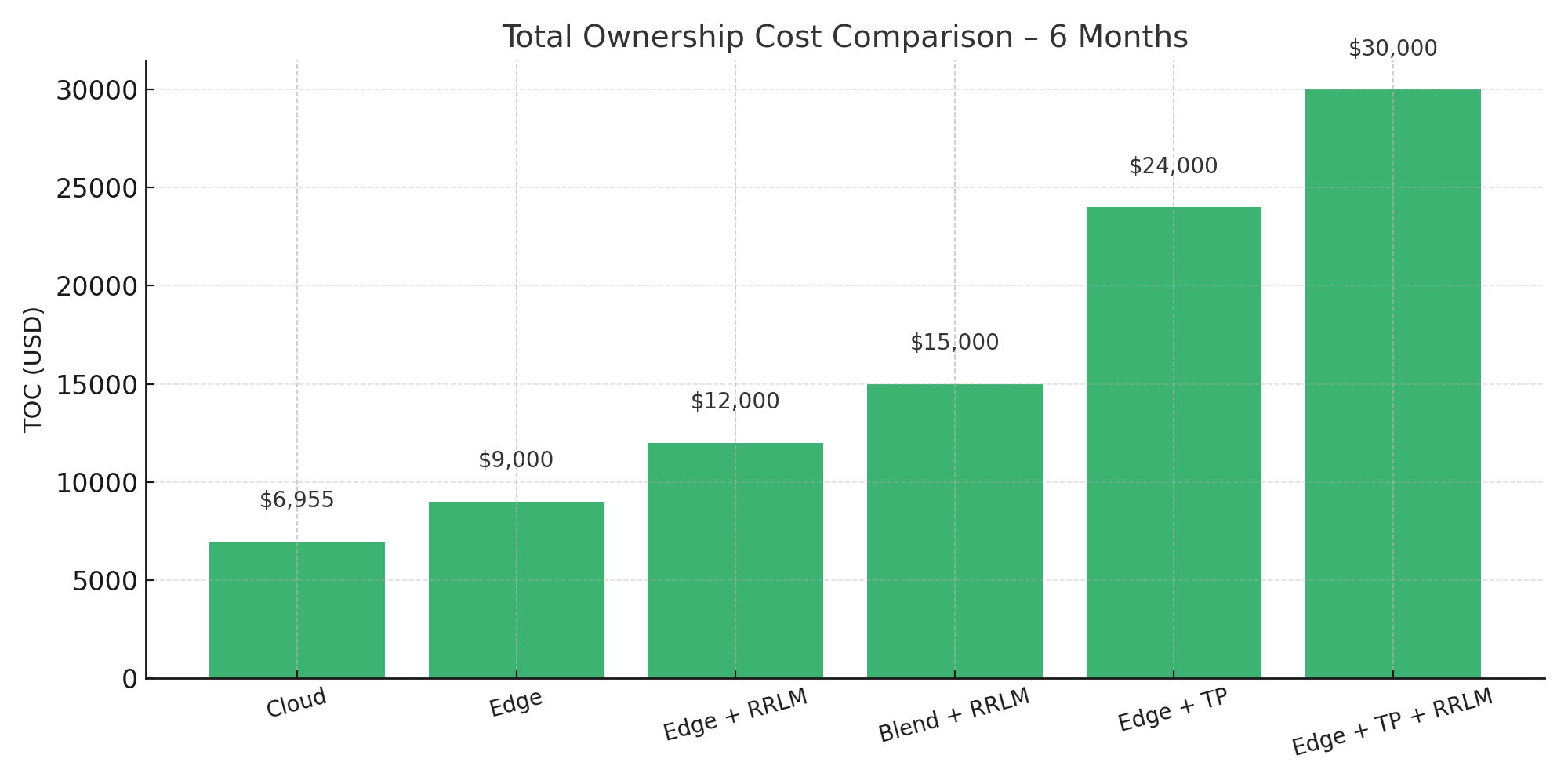
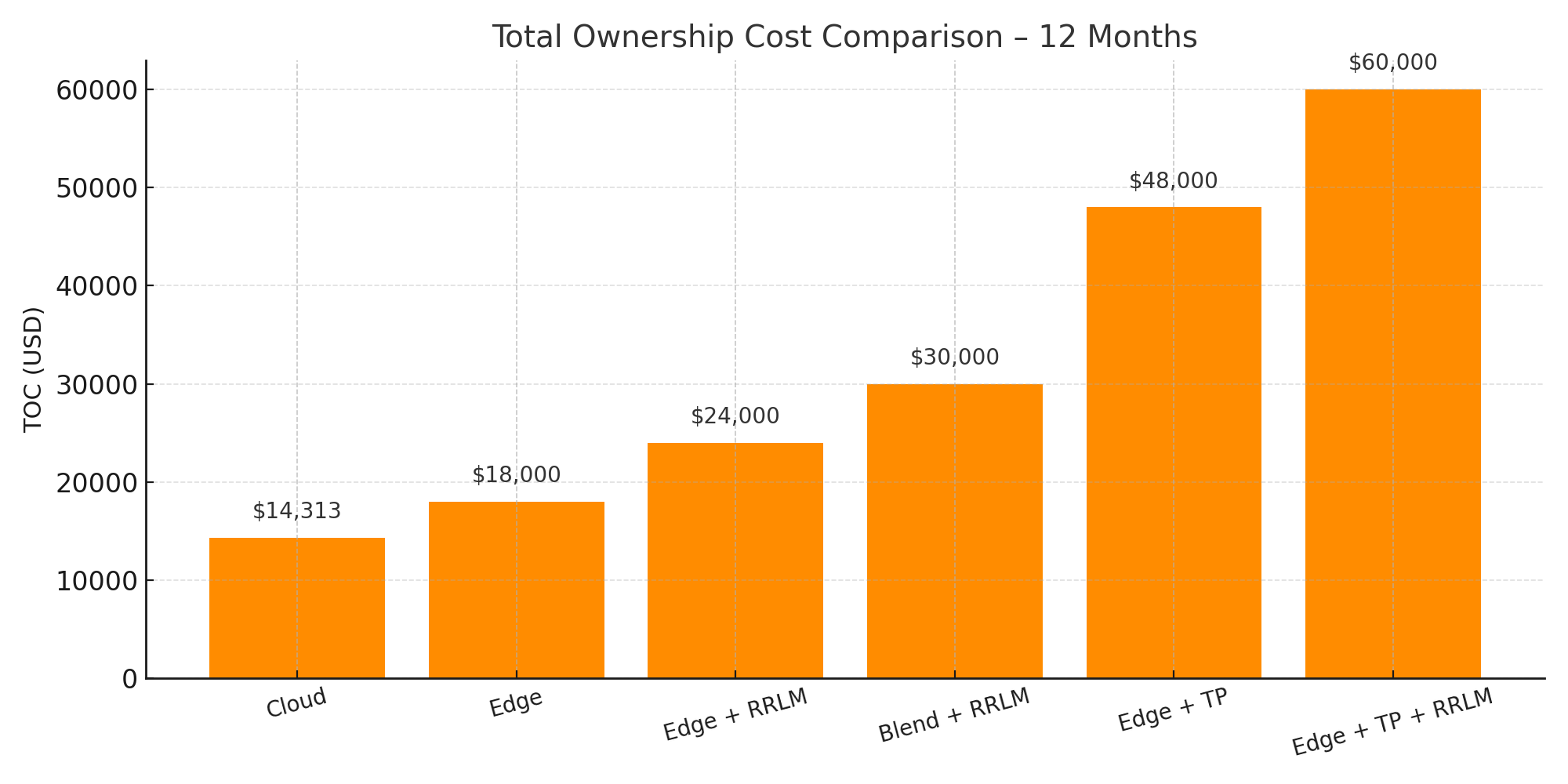
Visualize how each deployment option evolves in cost over 6, 12, and 36 months. Designed to help you choose not just the right starting point—but the right growth path.
Ready to take control of your AI strategy? LLMFuze offers flexible solutions tailored to your needs. Contact us today to discuss your requirements and find the perfect plan.